Pipeline de Integração e Processamento de Dados

1. Contexto
Em ambientes de dados complexos é comum enfrentar o desafio de integrar informações provenientes de diversas fontes — como bancos de dados relacionais e arquivos estruturados — de forma a garantir que os dados estejam limpos, consistentes e facilmente acessíveis para usos futuros. Este trabalho busca construir um pipeline de integração, tratamento, validação de qualidade, rastreabilidade, auditoria e geração automatizada de relatórios.
2. Objetivo
Desenvolver, em Python, um pipeline completo de engenharia de dados que seja capaz de integrar múltiplas fontes (PostgreSQL, SQLite, CSV e JSON), realizar a limpeza, transformação e padronização dos dados, e aplicar validações estruturais e de negócio. O pipeline também deve contemplar rastreabilidade via logs, controle de versão por meio de backups automáticos e geração de relatório final da execução. Tudo isso para garantir a confiabilidade, escalabilidade e reutilização dos dados nas etapas seguintes da arquitetura analítica.
3. Metodologia
Utilizaremos práticas de DataOps para implementar um pipeline de ETL/ELT que envolve:
- Extração: Conexão e coleta de dados de diversas fontes (PostgreSQL, SQLite, CSV, JSON).
- Transformação: Limpeza, padronização e enriquecimento dos dados por meio de validações, tratamento de outliers e conversão de tipos, garantindo a integridade dos registros.
- Carregamento: Integração dos dados processados em uma base consolidada, com mecanismos de armazenamento flexível e otimizado.
- Backup Automático e Controle de Versão: Para preservar o histórico das alterações e permitir a recuperação dos dados, aumentando a confiabilidade do pipeline.
- Monitoramento com Logs: Registro detalhado de cada etapa para garantir rastreabilidade e facilitar a identificação de falhas.
3.1 Configuração Inicial e Importação de Bibliotecas
Neste bloco inicial vamos configurar o sistema de logs para monitorar o pipeline de dados. Também vamos realizar a importação das bibliotecas necessárias e aplicar filtros para suprimir avisos desnecessários, garantindo um ambiente de execução mais limpo e monitorado.
# 1. Bibliotecas para manipulação de dados e machine learning
import json
import numpy as np
import pandas as pd
from scipy.stats import zscore
from sklearn.ensemble import IsolationForest
# 2. Conexão com bancos de dados relacionais
import sqlite3
from sqlalchemy import create_engine
# 3. Manipulação de arquivos e sistema
import os
import shutil
import sys
import time
from pathlib import Path
# 4. Configuração de logs com rotação, personalização e aviso
import logging
from logging.handlers import RotatingFileHandler
import warnings
from datetime import datetime
# Definindo o nível AUDIT (entre INFO e WARNING)
AUDIT_LEVEL_NUM = 25
logging.addLevelName(AUDIT_LEVEL_NUM, "AUDIT")
def audit(self, message, *args, **kwargs):
if self.isEnabledFor(AUDIT_LEVEL_NUM):
self._log(AUDIT_LEVEL_NUM, message, args, **kwargs)
logging.Logger.audit = audit
# Criando logger_custom() com cores e categorias
from colorama import Fore, Style, init
init(autoreset=True) # Auto reset para terminal
class CustomFormatter(logging.Formatter):
COLOR_MAP = {
"INFO": Fore.CYAN,
"AUDIT": Fore.GREEN,
"WARNING": Fore.YELLOW,
"ERROR": Fore.RED,
"CRITICAL": Fore.RED + Style.BRIGHT,
"DEBUG": Fore.MAGENTA
}
def format(self, record):
levelname = record.levelname
color = self.COLOR_MAP.get(levelname, "")
reset = Style.RESET_ALL
message = super().format(record)
return f"{color}{message}{reset}"
def logger_custom(diretorio_logs="logs", nome_arquivo="pipeline.log", nivel=logging.DEBUG):
try:
os.makedirs(diretorio_logs, exist_ok=True)
caminho_log = os.path.join(diretorio_logs, nome_arquivo)
formatter_padrao = logging.Formatter("%(asctime)s - [%(levelname)s] - %(name)s - %(message)s")
formatter_terminal = CustomFormatter("%(asctime)s - [%(levelname)s] - %(message)s")
# File Handler com rotação
handler_arquivo = RotatingFileHandler(caminho_log, maxBytes=5 * 1024 * 1024, backupCount=3)
handler_arquivo.setFormatter(formatter_padrao)
# Console Handler com cor
handler_console = logging.StreamHandler()
handler_console.setFormatter(formatter_terminal)
logger = logging.getLogger()
logger.setLevel(nivel)
# Evitar handlers duplicados
if not logger.hasHandlers():
logger.addHandler(handler_arquivo)
logger.addHandler(handler_console)
logger.info(f"Ambiente customizado de logs configurado com sucesso em: {caminho_log}")
except Exception as e:
print(f"❌ Erro ao configurar logger customizado: {str(e)}")
def configurar_logs(diretorio_logs=Path.cwd() / "logs", nome_arquivo="pipeline.log", nivel=logging.DEBUG):
"""
Configura sistema de logging com rotação automática, saída no console
e nível personalizável para rastreabilidade desde o início do pipeline.
Parâmetros:
diretorio_logs (str): Diretório onde os arquivos de log serão armazenados.
nome_arquivo (str): Nome do arquivo principal de log.
nivel (int): Nível mínimo de log (DEBUG, INFO, WARNING, ERROR, CRITICAL).
Retorno:
None
"""
try:
# 1. Criação do diretório de logs
os.makedirs(diretorio_logs, exist_ok=True)
# 2. Formato do log
formato_log = logging.Formatter(
"%(asctime)s - [%(levelname)s] - %(name)s - %(message)s"
)
# 3. Configuração do handler de arquivo com rotação
caminho_log = os.path.join(diretorio_logs, nome_arquivo)
handler_arquivo = RotatingFileHandler(
caminho_log, maxBytes=5 * 1024 * 1024, backupCount=3
)
handler_arquivo.setFormatter(formato_log)
# 4. Handler de console
handler_console = logging.StreamHandler()
handler_console.setFormatter(formato_log)
# 5. Logger principal
logger = logging.getLogger()
if not logger.hasHandlers():
logger.setLevel(nivel)
logger.addHandler(handler_arquivo)
logger.addHandler(handler_console)
logging.info(f"Ambiente de logs configurado com sucesso em: {caminho_log}")
except Exception as e:
print(f"Erro ao configurar logs: {str(e)}")
raise
# Executando a configuração inicial de logs
logger_custom()
# 5. Suprimindo avisos irrelevantes
warnings.filterwarnings("ignore", category=UserWarning, module="sqlalchemy")
warnings.filterwarnings("ignore", category=FutureWarning)
# 6. Adicionando caminho da pasta 'scripts' ao sys.path (caso uso de módulos auxiliares)
sys.path.append(os.path.abspath(os.path.join(os.getcwd(), "..", "scripts")))
# 7. Importação segura de credenciais de banco (PostgreSQL)
try:
from config import banco, host, senha, usuario
except ModuleNotFoundError:
logging.error(
"Arquivo 'config.py' não encontrado. Verifique o caminho e tente novamente."
)
raise
2025-07-13 16:03:17,645 - [INFO] - Ambiente customizado de logs configurado com sucesso em: logs\pipeline.log
# Função auxiliar para apresentar moldura de texto no console
def moldura_texto(texto):
# Lista que não serão capitalizadas
preposicoes = [
"de",
"da",
"do",
"das",
"dos",
"em",
"para",
"com",
"por",
"sem",
"sob",
"sobre",
"as",
"a",
"o",
"e",
"à",
"às",
"ao",
"no",
"na",
"nos",
"nas",
]
# Formatamos o texto inicial maiúscula, exceto preposições
palavras = texto.split()
texto_formatado = " ".join(
palavra.capitalize() if palavra.lower() not in preposicoes else palavra
for palavra in palavras
)
# adicionamos negrito usando ANSI Escape Codes
texto_negrito = f"\033[1m{texto_formatado}\033[0m"
# adicionamos moldura ao texto
moldura = "-" * 23
resultado = f"\n{moldura}>>>> {texto_negrito} <<<<{moldura}\n"
print(resultado)
3.2 Visualização da Estrutura Interna do Pipeline
Para compreender melhor a arquitetura lógica deste pipeline, disponiblizamos no botão abaixo para visualização o mapa interativo de dependências técnicas utilizadas ao longo do projeto.
📦 Estrutura do Pipeline de Integração e Processamento de Dados
pipeline_de_integracao_e_processamento_de_dados
├── [3.1] configurar_logs() → Configura logs com rotação automática e nível DEBUG
├── [4.1] carregar_dados() → Extrai dados de PostgreSQL, SQLite, CSV, JSON
│ └── Usa credenciais de config.py
├── [4.3] transformar_dados() → Padroniza canais, tipo_acesso, cria faixa_idade, faixa_valor, ano
├── [4.4] tratar_qualidade_dados() → Remove duplicatas, preenche nulos, corrige outliers, valida e-mails
├── [4.5] unir_bases() → Realiza inner/left joins, valida chaves e calcula perdas
├── [4.6] gerar_resumo_estatistico() → Analisa distribuições, médias, intervalos por coluna
├── [4.7] validar_tratar_dados_integrados() → Reintegra registros ausentes e ajusta tipos
├── [4.8] validar_e_testar_qualidade() → Finaliza preenchimento e confirma integridade da base
├── [4.9] armazenar_dados() → Exporta os dados tratados em formatos CSV, JSON e Parquet
├── [5] gerar_backup() → Salva versão histórica com timestamp
├── [6] concluir_pipeline() → Gera relatório automatizado (relatorio_pipeline.txt)
│ └── Executa auditoria via auditar_qualidade_dados()
└── [7] Estrutura de Arquivos → logs/, dados/output/, dados/backup/
🧾 Arquivos Suplementares:
- config.py → Fornece credenciais PostgreSQL
- validacao_dados.py → Regras de estrutura e negócio para auditoria final
4. Carregamento de Dados
Neste bloco vamos estabelecer conexões com diferentes fontes de dados, como bancos relacionais e arquivos estruturados. Também vamos validar a existência dos arquivos e formatos, registrando logs detalhados para monitorar cada etapa do carregamento, garantindo a integridade e a disponibilidade das informações.
# Função para carregar dados de múltiplas fontes (SQLite, PostgreSQL, CSV, JSON)
def carregar_dados(fonte, tipo, query=None, caminho=None):
"""
Carrega dados de diferentes formatos e origens.
Parâmetros:
fonte (str): Nome da fonte de dados (para logs).
tipo (str): Tipo da origem: 'sqlite', 'postgresql', 'csv' ou 'json'.
query (str): Consulta SQL (obrigatória para banco).
caminho (str): Caminho do arquivo (obrigatório para arquivo).
Retorno:
pd.DataFrame: base de dados carregada.
"""
try:
if tipo in ["sqlite", "csv", "json"]:
if caminho is None:
raise ValueError(f"Caminho é obrigatório para a fonte '{tipo}'.")
caminho = Path(caminho).resolve()
if not caminho.exists():
raise FileNotFoundError(f"Arquivo '{caminho}' não encontrado.")
df = None
if tipo == "sqlite":
conn = sqlite3.connect(str(caminho))
df = pd.read_sql(query, conn)
conn.close()
log_msg = f"SQLite ({fonte}) carregado com sucesso!"
elif tipo == "postgresql":
engine = create_engine(f"postgresql://{usuario}:{senha}@{host}/{banco}")
df = pd.read_sql(query, engine)
log_msg = f"PostgreSQL ({fonte}) carregado com sucesso!"
elif tipo == "csv":
df = pd.read_csv(str(caminho))
log_msg = f"Arquivo CSV ({fonte}) carregado com sucesso!"
elif tipo == "json":
df = pd.read_json(caminho, lines=True)
log_msg = f"Arquivo JSON ({fonte}) carregado com sucesso!"
else:
raise ValueError(f"Tipo '{tipo}' não suportado.")
logging.info(log_msg)
return df
except Exception as e:
logging.error(f"Erro ao carregar dados de {fonte}: {e}")
raise
# Carregamento das bases
clientes_df = carregar_dados(
fonte="Clientes do SQLite",
tipo="sqlite",
query="SELECT * FROM clientes",
caminho="dados/clientes.db",
)
vendas_df = carregar_dados(
fonte="Vendas do PostgreSQL", tipo="postgresql", query="SELECT * FROM vendas"
)
marketing_df = carregar_dados(
fonte="Marketing do arquivo CSV", tipo="csv", caminho="dados/marketing.csv"
)
acessos_df = carregar_dados(
fonte="Histórico de Acessos do JSON",
tipo="json",
caminho="dados/historico_acessos.json",
)
# Moldura e resumo das dimensões
moldura_texto("Resumo dos Dados Carregados:")
print(f"\nClientes: {clientes_df.shape}")
print(f"Vendas: {vendas_df.shape}")
print(f"Marketing: {marketing_df.shape}")
print(f"Histórico de Acessos: {acessos_df.shape}")
2025-07-13 16:03:17,929 - [INFO] - SQLite (Clientes do SQLite) carregado com sucesso! 2025-07-13 16:03:18,084 - [INFO] - PostgreSQL (Vendas do PostgreSQL) carregado com sucesso! 2025-07-13 16:03:18,093 - [INFO] - Arquivo CSV (Marketing do arquivo CSV) carregado com sucesso! 2025-07-13 16:03:18,109 - [INFO] - Arquivo JSON (Histórico de Acessos do JSON) carregado com sucesso!
----------------------->>>> Resumo dos Dados Carregados: <<<<----------------------- Clientes: (5000, 4) Vendas: (5000, 4) Marketing: (5000, 5) Histórico de Acessos: (5000, 4)
4.2 Exploração da Estrutura Inicial das Tabelas Carregadas
Agora que já carregamos os dados, vamos explorar a estrutura das tabelas carregadas. Também vamos analisar a quantidade de registros, os tipos de dados e os valores nulos em cada coluna, garantindo que os dados estão organizados e prontos para os próximos passos do pipeline.
# Explorando a estrutura de cada base
moldura_texto("Informações dos dados de Clientes")
print(clientes_df.info())
moldura_texto("Informações dos dados de Vendas")
print(vendas_df.info())
moldura_texto("Informações dos dados de Marketing")
print(marketing_df.info())
moldura_texto("Informações dos dados de Acessos")
print(acessos_df.info())
----------------------->>>> Informações dos Dados de Clientes <<<<----------------------- <class 'pandas.core.frame.DataFrame'> RangeIndex: 5000 entries, 0 to 4999 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 cliente_id 5000 non-null int64 1 nome 5000 non-null object 2 idade 5000 non-null int64 3 email 5000 non-null object dtypes: int64(2), object(2) memory usage: 156.4+ KB None ----------------------->>>> Informações dos Dados de Vendas <<<<----------------------- <class 'pandas.core.frame.DataFrame'> RangeIndex: 5000 entries, 0 to 4999 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 venda_id 5000 non-null int64 1 cliente_id 5000 non-null int64 2 data_venda 5000 non-null object 3 valor 5000 non-null float64 dtypes: float64(1), int64(2), object(1) memory usage: 156.4+ KB None ----------------------->>>> Informações dos Dados de Marketing <<<<----------------------- <class 'pandas.core.frame.DataFrame'> RangeIndex: 5000 entries, 0 to 4999 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 campanha_id 5000 non-null int64 1 cliente_id 5000 non-null int64 2 canal 4501 non-null object 3 data_envio 5000 non-null object 4 resposta 5000 non-null bool dtypes: bool(1), int64(2), object(2) memory usage: 161.3+ KB None ----------------------->>>> Informações dos Dados de Acessos <<<<----------------------- <class 'pandas.core.frame.DataFrame'> RangeIndex: 5000 entries, 0 to 4999 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 cliente_id 5000 non-null int64 1 data_acesso 5000 non-null int64 2 tipo_acesso 5000 non-null object 3 duracao_minutos 5000 non-null int64 dtypes: int64(3), object(1) memory usage: 156.4+ KB None
4.3 Transformações Avançadas com Validações e Enriquecimento de Dados
Vamos definir neste bloco a função que será utilizada posteriormente para aplicar transformações avançadas sobre os dados, incluindo padronização e enriquecimento. Dessa forma a função será invocada nas etapas finais do pipeline para garantir consistência e qualidade analítica.
def transformar_dados(df, nome_base):
"""
Realiza transformações avançadas e enriquecimento dos dados.
Parâmetros:
df (pd.DataFrame): base a ser transformada.
nome_base (str): nome da base para controle de logs.
Retorno:
pd.DataFrame: base transformada.
"""
logging.info(f"Iniciando transformações avançadas para a base '{nome_base}'.")
# Padronização de tipo_acesso
if "tipo_acesso" in df.columns:
antes = df["tipo_acesso"].nunique()
df["tipo_acesso"] = df["tipo_acesso"].str.lower().str.capitalize()
depois = df["tipo_acesso"].nunique()
logging.info(
f"Coluna 'tipo_acesso' padronizada. Valores únicos alterados de {antes} para {depois}."
)
# Padronização de canal
if "canal" in df.columns:
antes_nulos = df["canal"].isnull().sum()
df["canal"] = df["canal"].str.upper().fillna("NÃO INFORMADO")
depois_nulos = df["canal"].isnull().sum()
logging.info(
f"Coluna 'canal' padronizada. Valores nulos corrigidos: {antes_nulos - depois_nulos}."
)
# Coluna derivada: faixa_valor
if "valor" in df.columns:
df["faixa_valor"] = pd.cut(
df["valor"], bins=[0, 100, 500, 1000], labels=["Baixo", "Médio", "Alto"]
)
logging.info("Coluna derivada 'faixa_valor' criada com faixas definidas.")
# Coluna derivada: ano
if "data_venda" in df.columns:
df["ano"] = pd.to_datetime(df["data_venda"], errors="coerce").dt.year
logging.info("Coluna 'ano' criada com base na 'data_venda'.")
# Coluna derivada: faixa_idade
if "idade" in df.columns:
df["faixa_idade"] = pd.cut(
df["idade"],
bins=[18, 30, 45, 60, 100],
labels=["Jovem", "Adulto", "Meia Idade", "Idoso"],
)
logging.info("Coluna derivada 'faixa_idade' criada para segmentação etária.")
novas_colunas = [
col for col in ["faixa_valor", "ano", "faixa_idade"] if col in df.columns
]
logging.info(
f"Transformações concluídas para '{nome_base}'. Novas colunas criadas: {novas_colunas}"
)
return df
4.4 Limpeza Individual das Bases
Vamos realizar neste bloco a limpeza individual de cada base de dados. Vamos tratar duplicatas, corrigir valores ausentes e identificar outliers utilizando métodos estatísticos, como Z-Score e Isolation Forest. Também vamos ajustar os tipos de dados para manter a consistência e a qualidade das informações processadas.
def tratar_qualidade_dados(
df, nome_base, contexto="base_separada", metodo_outlier="zscore", limiar_zscore=3
):
"""
Realiza análise e tratamento de qualidade dos dados.
Parâmetros:
df (pd.DataFrame): base a ser tratada.
nome_base (str): nome identificador para logs.
contexto (str): 'base_separada' ou 'base_integrada'.
metodo_outlier (str): 'zscore' ou 'isolation_forest'.
limiar_zscore (float): limite para z-score (default = 3).
Retorno:
pd.DataFrame: base tratada e validada.
"""
if df is None or df.empty:
logging.warning(
f"Base '{nome_base}' está nula ou vazia. Tratamento será ignorado."
)
return df
logging.info(
f"Iniciando tratamento de qualidade para {nome_base.upper()} ({contexto})."
)
# 1. Remoção de duplicatas
duplicatas = df.duplicated().sum()
if duplicatas > 0:
df = df.drop_duplicates()
logging.info(f"{duplicatas} duplicatas removidas na base '{nome_base}'.")
# 2. Tratamento de valores ausentes
nulos = df.isnull().sum()
if nulos.any():
logging.info(f"Valores ausentes detectados em {nome_base}:\n{nulos[nulos > 0]}")
for coluna in df.columns:
if df[coluna].isnull().sum() > 0:
if df[coluna].dtype in ["float64", "int64"]:
valor = df[coluna].median()
df[coluna].fillna(valor, inplace=True)
logging.info(
f"Preenchido com mediana ({valor}) os nulos da coluna '{coluna}'."
)
elif df[coluna].dtype == "object":
df[coluna].fillna("Não Informado", inplace=True)
logging.info(
f"Preenchido com 'Não Informado' os nulos da coluna '{coluna}'."
)
# 3. Tratamento de outliers
if metodo_outlier == "zscore":
for col in df.select_dtypes(include=["float64", "int64"]).columns:
z = zscore(df[col])
outliers = np.abs(z) > limiar_zscore
if outliers.sum() > 0:
df.loc[outliers, col] = df[col].median()
logging.info(f"Outliers corrigidos na coluna '{col}' com Z-Score.")
elif metodo_outlier == "isolation_forest":
modelo = IsolationForest(contamination=0.05, random_state=42)
for col in df.select_dtypes(include=["float64", "int64"]).columns:
outliers = modelo.fit_predict(df[[col]]) == -1
if outliers.sum() > 0:
df.loc[outliers, col] = df[col].median()
logging.info(
f"Outliers corrigidos na coluna '{col}' com Isolation Forest."
)
# 4. Regras específicas para base integrada
if contexto == "base_integrada":
if "duracao_minutos" in df.columns:
df["duracao_minutos"].fillna(0, inplace=True)
logging.info("Campo 'duracao_minutos' preenchido com 0.")
if "resposta" in df.columns:
df["resposta"].fillna("Não", inplace=True)
logging.info("Campo 'resposta' preenchido com 'Não'.")
# 5. Faixa de restrição para colunas críticas
if "idade" in df.columns:
df["idade"] = df["idade"].clip(lower=18, upper=100)
logging.info("Limites aplicados na coluna 'idade' (18 a 100).")
if "valor" in df.columns:
df["valor"] = df["valor"].clip(lower=0, upper=1000)
logging.info("Limites aplicados na coluna 'valor' (0 a 1000).")
# 6. Validação simples de e-mails
if "email" in df.columns:
emails_invalidos = df[~df["email"].astype(str).str.contains("@", na=False)]
if not emails_invalidos.empty:
logging.warning(
f"E-mails inválidos detectados: {len(emails_invalidos)} registros."
)
df["email"] = df["email"].apply(
lambda x: None if isinstance(x, str) and "@" not in x else x
)
logging.info(f"Tratamento concluído para '{nome_base.upper()}' ({contexto}).")
return df
# Aplicação da limpeza individual nas bases separadas
clientes_df = tratar_qualidade_dados(clientes_df, "Clientes", contexto="base_separada")
vendas_df = tratar_qualidade_dados(
vendas_df, "Vendas", contexto="base_separada", metodo_outlier="isolation_forest"
)
marketing_df = tratar_qualidade_dados(
marketing_df, "Marketing", contexto="base_separada"
)
acessos_df = tratar_qualidade_dados(
acessos_df, "Acessos", contexto="base_separada", metodo_outlier="isolation_forest"
)
2025-07-13 16:03:19,005 - [INFO] - Iniciando tratamento de qualidade para CLIENTES (base_separada). 2025-07-13 16:03:19,014 - [INFO] - Limites aplicados na coluna 'idade' (18 a 100). 2025-07-13 16:03:19,020 - [INFO] - Tratamento concluído para 'CLIENTES' (base_separada). 2025-07-13 16:03:19,022 - [INFO] - Iniciando tratamento de qualidade para VENDAS (base_separada). 2025-07-13 16:03:19,176 - [INFO] - Outliers corrigidos na coluna 'venda_id' com Isolation Forest. 2025-07-13 16:03:19,363 - [INFO] - Outliers corrigidos na coluna 'cliente_id' com Isolation Forest. 2025-07-13 16:03:19,547 - [INFO] - Outliers corrigidos na coluna 'valor' com Isolation Forest. 2025-07-13 16:03:19,552 - [INFO] - Limites aplicados na coluna 'valor' (0 a 1000). 2025-07-13 16:03:19,554 - [INFO] - Tratamento concluído para 'VENDAS' (base_separada). 2025-07-13 16:03:19,558 - [INFO] - Iniciando tratamento de qualidade para MARKETING (base_separada). 2025-07-13 16:03:19,564 - [INFO] - Valores ausentes detectados em Marketing: canal 499 dtype: int64 2025-07-13 16:03:19,567 - [INFO] - Preenchido com 'Não Informado' os nulos da coluna 'canal'. 2025-07-13 16:03:19,571 - [INFO] - Tratamento concluído para 'MARKETING' (base_separada). 2025-07-13 16:03:19,574 - [INFO] - Iniciando tratamento de qualidade para ACESSOS (base_separada). 2025-07-13 16:03:19,768 - [INFO] - Outliers corrigidos na coluna 'cliente_id' com Isolation Forest. 2025-07-13 16:03:19,957 - [INFO] - Outliers corrigidos na coluna 'data_acesso' com Isolation Forest. 2025-07-13 16:03:20,135 - [INFO] - Outliers corrigidos na coluna 'duracao_minutos' com Isolation Forest. 2025-07-13 16:03:20,138 - [INFO] - Tratamento concluído para 'ACESSOS' (base_separada).
4.5 União Dinâmica e Flexível de Bases para Análises Completas
Chegamos ao momento de unir as bases carregadas em uma estrutura integrada para futuras análises mais completas. Antes da união, vamos garantir a consistência dos tipos de dados nas chaves, aplicando conversões explícitas para inteiros. Também vamos remover duplicatas mantendo apenas a primeira ocorrência, preservando a integridade dos registros. Após a união, vamos verificar se existem registros que não possuem correspondência entre as bases e registrar essas informações nos logs para futura análise.
def unir_bases(
base_esquerda,
base_direita,
chave,
tipo_uniao="inner",
nome_base_esquerda="Base Esquerda",
nome_base_direita="Base Direita",
):
"""
Realiza a união dinâmica entre duas bases de dados.
Parâmetros:
base_esquerda (pd.DataFrame): primeira base.
base_direita (pd.DataFrame): segunda base.
chave (list): lista de colunas-chave para união.
tipo_uniao (str): tipo de união ('inner', 'left', etc.).
nome_base_esquerda (str): nome da base 1 para logs.
nome_base_direita (str): nome da base 2 para logs.
Retorno:
pd.DataFrame: base integrada.
"""
logger = logging.getLogger()
logger.info(f"Iniciando união entre '{nome_base_esquerda}' e '{nome_base_direita}'.")
try:
# Diagnóstico inicial
if base_esquerda is None or base_direita is None:
logger.error("Uma das bases fornecidas é 'None'.")
raise ValueError("Base nula identificada.")
if base_esquerda.empty:
logger.warning(f"A base '{nome_base_esquerda}' está vazia.")
else:
logger.info(f"Base '{nome_base_esquerda}' possui {base_esquerda.shape[0]} registros.")
if base_direita.empty:
logger.warning(f"A base '{nome_base_direita}' está vazia.")
else:
logger.info(f"Base '{nome_base_direita}' possui {base_direita.shape[0]} registros.")
# Validação das chaves
chaves_invalidas = [
col for col in chave
if col not in base_esquerda.columns or col not in base_direita.columns
]
if chaves_invalidas:
logger.error(f"Chaves inválidas: {chaves_invalidas}")
raise ValueError(f"Chaves não encontradas: {chaves_invalidas}")
logger.info(f"Chaves validadas: {chave}")
# Padronização de tipo e remoção de duplicatas
for col in chave:
base_esquerda[col] = base_esquerda[col].astype(str)
base_direita[col] = base_direita[col].astype(str)
logger.info(f"Coluna '{col}' convertida para string.")
antes_esq = base_esquerda.shape[0]
antes_dir = base_direita.shape[0]
base_esquerda = base_esquerda.drop_duplicates(subset=chave, keep="first")
base_direita = base_direita.drop_duplicates(subset=chave, keep="first")
logger.info(f"Duplicatas removidas em '{nome_base_esquerda}': {antes_esq - base_esquerda.shape[0]}")
logger.info(f"Duplicatas removidas em '{nome_base_direita}': {antes_dir - base_direita.shape[0]}")
# União
base_integrada = pd.merge(
base_esquerda,
base_direita,
on=chave,
how=tipo_uniao,
indicator=True
)
logger.info(f"União '{tipo_uniao}' realizada com sucesso.")
# Diagnóstico com nível personalizado AUDIT
logger.audit(f"Registros apenas na base esquerda: {(base_integrada['_merge'] == 'left_only').sum()}")
logger.audit(f"Registros apenas na base direita: {(base_integrada['_merge'] == 'right_only').sum()}")
# Limpeza do indicador
base_integrada.drop(columns=["_merge"], inplace=True)
logger.info(f"Base integrada contém {base_integrada.shape[0]} registros após união.")
return base_integrada
except Exception as e:
logger.error(f"Erro ao unir bases: {str(e)}")
raise
# Execucao das Oniões
# 🔹 1ª união: Vendas + Clientes
dados_integrados = unir_bases(
vendas_df,
clientes_df,
chave=["cliente_id"],
tipo_uniao="inner",
nome_base_esquerda="Vendas",
nome_base_direita="Clientes",
)
# 🔹 2ª união: + Acessos
dados_integrados = unir_bases(
dados_integrados,
acessos_df,
chave=["cliente_id"],
tipo_uniao="left",
nome_base_esquerda="Dados Integrados",
nome_base_direita="Acessos",
)
# 🔹 3ª união: + Marketing
dados_integrados = unir_bases(
dados_integrados,
marketing_df,
chave=["cliente_id"],
tipo_uniao="left",
nome_base_esquerda="Dados Integrados",
nome_base_direita="Marketing",
)
2025-07-13 16:03:20,156 - [INFO] - Iniciando união entre 'Vendas' e 'Clientes'. 2025-07-13 16:03:20,160 - [INFO] - Base 'Vendas' possui 5000 registros. 2025-07-13 16:03:20,166 - [INFO] - Base 'Clientes' possui 5000 registros. 2025-07-13 16:03:20,169 - [INFO] - Chaves validadas: ['cliente_id'] 2025-07-13 16:03:20,179 - [INFO] - Coluna 'cliente_id' convertida para string. 2025-07-13 16:03:20,187 - [INFO] - Duplicatas removidas em 'Vendas': 1995 2025-07-13 16:03:20,190 - [INFO] - Duplicatas removidas em 'Clientes': 0 2025-07-13 16:03:20,201 - [INFO] - União 'inner' realizada com sucesso. 2025-07-13 16:03:20,204 - [AUDIT] - Registros apenas na base esquerda: 0 2025-07-13 16:03:20,208 - [AUDIT] - Registros apenas na base direita: 0 2025-07-13 16:03:20,212 - [INFO] - Base integrada contém 3005 registros após união. 2025-07-13 16:03:20,214 - [INFO] - Iniciando união entre 'Dados Integrados' e 'Acessos'. 2025-07-13 16:03:20,217 - [INFO] - Base 'Dados Integrados' possui 3005 registros. 2025-07-13 16:03:20,219 - [INFO] - Base 'Acessos' possui 5000 registros. 2025-07-13 16:03:20,222 - [INFO] - Chaves validadas: ['cliente_id'] 2025-07-13 16:03:20,227 - [INFO] - Coluna 'cliente_id' convertida para string. 2025-07-13 16:03:20,231 - [INFO] - Duplicatas removidas em 'Dados Integrados': 0 2025-07-13 16:03:20,233 - [INFO] - Duplicatas removidas em 'Acessos': 2044 2025-07-13 16:03:20,242 - [INFO] - União 'left' realizada com sucesso. 2025-07-13 16:03:20,244 - [AUDIT] - Registros apenas na base esquerda: 1163 2025-07-13 16:03:20,246 - [AUDIT] - Registros apenas na base direita: 0 2025-07-13 16:03:20,249 - [INFO] - Base integrada contém 3005 registros após união. 2025-07-13 16:03:20,251 - [INFO] - Iniciando união entre 'Dados Integrados' e 'Marketing'. 2025-07-13 16:03:20,253 - [INFO] - Base 'Dados Integrados' possui 3005 registros. 2025-07-13 16:03:20,256 - [INFO] - Base 'Marketing' possui 5000 registros. 2025-07-13 16:03:20,258 - [INFO] - Chaves validadas: ['cliente_id'] 2025-07-13 16:03:20,264 - [INFO] - Coluna 'cliente_id' convertida para string. 2025-07-13 16:03:20,271 - [INFO] - Duplicatas removidas em 'Dados Integrados': 0 2025-07-13 16:03:20,274 - [INFO] - Duplicatas removidas em 'Marketing': 1811 2025-07-13 16:03:20,287 - [INFO] - União 'left' realizada com sucesso. 2025-07-13 16:03:20,291 - [AUDIT] - Registros apenas na base esquerda: 1082 2025-07-13 16:03:20,292 - [AUDIT] - Registros apenas na base direita: 0 2025-07-13 16:03:20,298 - [INFO] - Base integrada contém 3005 registros após união.
4.6 Geração de Resumo Estatístico Pós-Processamento
Vamos gerar neste bloco resumo estatístico detalhado dos dados integrados. Esse processo inclui medidas como média, mediana, valores mínimos e máximos, além de verificar a distribuição dos dados. Essa análise nos permite identificar padrões, variações e possíveis inconsistências antes de avançarmos para as etapas finais do pipeline.
def gerar_resumo_estatistico(df, nome_base="Base Integrada"):
"""
Gera resumo estatístico de colunas numéricas, categóricas e temporais.
Parâmetros:
df (pd.DataFrame): base de dados.
nome_base (str): nome da base para título e logs.
Retorno:
None
"""
logger = logging.getLogger()
if df is None or df.empty:
logger.warning(f"A base '{nome_base}' está vazia. Resumo estatístico não será gerado.")
print(f"\nA base '{nome_base}' está vazia.\n")
return
logger.info(f"Gerando resumo estatístico para '{nome_base}' com {df.shape[0]} registros.")
moldura_texto(f"Resumo Estatístico - {nome_base}")
# Separar colunas por tipo
colunas_numericas = df.select_dtypes(include=["number"]).columns.tolist()
colunas_categoricas = df.select_dtypes(include=["object", "category"]).columns.tolist()
colunas_datetime = df.select_dtypes(include=["datetime64"]).columns.tolist()
# Resumo geral
print("Estatísticas descritivas (geral):\n")
print(df[colunas_numericas + colunas_categoricas].describe(include="all"))
# Específicos para datas
for col in colunas_datetime:
print(f"\nIntervalo de datas na coluna '{col}':")
print(df[col].describe(datetime_is_numeric=False))
logger.info(f"Estatísticas temporais da coluna '{col}' exibidas.")
# Resumo por coluna de interesse
colunas_detalhadas = ["duracao_minutos", "valor", "idade"]
for coluna in colunas_detalhadas:
if coluna in df.columns:
print(f"\nIntervalo de '{coluna}':")
print(df[coluna].describe())
logger.audit(f"Resumo estatístico de '{coluna}' gerado com distribuição, média e faixa.")
gerar_resumo_estatistico(dados_integrados, nome_base="Base Integrada Atualizada")
2025-07-13 16:03:20,498 - [INFO] - Gerando resumo estatístico para 'Base Integrada Atualizada' com 3005 registros.
----------------------->>>> Resumo Estatístico - Base Integrada Atualizada <<<<-----------------------
Estatísticas descritivas (geral):
venda_id valor idade data_acesso duracao_minutos \
count 3005.000000 3005.000000 3005.000000 1.842000e+03 1842.000000
unique NaN NaN NaN NaN NaN
top NaN NaN NaN NaN NaN
freq NaN NaN NaN NaN NaN
mean 2125.873877 501.098988 46.323794 1.719141e+12 92.598263
std 1305.861497 265.967801 16.495449 1.708510e+10 46.891305
min 114.000000 33.570000 18.000000 1.688256e+12 9.000000
25% 982.000000 276.070000 32.000000 1.704413e+12 54.000000
50% 2039.000000 506.110000 46.000000 1.719878e+12 92.000000
75% 3083.000000 727.390000 61.000000 1.733789e+12 132.000000
max 4864.000000 968.500000 74.000000 1.749082e+12 175.000000
campanha_id cliente_id data_venda nome email \
count 1923.000000 3005 3005 3005 3005
unique NaN 3005 1460 2888 2960
top NaN 2768 2020-12-30 Gael Fogaça qbarros@example.com
freq NaN 1 7 2 3
mean 2107.047322 NaN NaN NaN NaN
std 1418.614829 NaN NaN NaN NaN
min 3.000000 NaN NaN NaN NaN
25% 865.000000 NaN NaN NaN NaN
50% 1906.000000 NaN NaN NaN NaN
75% 3273.000000 NaN NaN NaN NaN
max 5000.000000 NaN NaN NaN NaN
tipo_acesso canal data_envio resposta
count 1842 1923 1923 1923
unique 2 4 905 2
top Web EMAIL 2023-05-27 True
freq 924 807 7 990
mean NaN NaN NaN NaN
std NaN NaN NaN NaN
min NaN NaN NaN NaN
25% NaN NaN NaN NaN
50% NaN NaN NaN NaN
75% NaN NaN NaN NaN
max NaN NaN NaN NaN
Intervalo de 'duracao_minutos':
count 1842.000000
mean 92.598263
std 46.891305
min 9.000000
25% 54.000000
50% 92.000000
75% 132.000000
max 175.000000
Name: duracao_minutos, dtype: float64
2025-07-13 16:03:20,539 - [AUDIT] - Resumo estatístico de 'duracao_minutos' gerado com distribuição, média e faixa.
Intervalo de 'valor': count 3005.000000 mean 501.098988 std 265.967801 min 33.570000 25% 276.070000 50% 506.110000 75% 727.390000 max 968.500000 Name: valor, dtype: float64
2025-07-13 16:03:20,547 - [AUDIT] - Resumo estatístico de 'valor' gerado com distribuição, média e faixa.
Intervalo de 'idade': count 3005.000000 mean 46.323794 std 16.495449 min 18.000000 25% 32.000000 50% 46.000000 75% 61.000000 max 74.000000 Name: idade, dtype: float64
2025-07-13 16:03:20,555 - [AUDIT] - Resumo estatístico de 'idade' gerado com distribuição, média e faixa.
4.7 Validação Pós-Integração e Tratamento de Dados Consolidados
Vamos dar uma última revisada nos dados integrados, verificando se tudo está no lugar e corrigindo qualquer inconsistência que tenha passado despercebida. Neste bloco, também vamos reintegrar clientes que ficaram de fora da base consolidada, preencher campos com valores padrão, ajustar tipos de dados e revisar colunas críticas para garantir que a estrutura final esteja pronta para os estágios de validação final e exportação.
def validar_tratar_dados_integrados(dados_integrados, clientes_df):
"""
Valida e ajusta a base integrada final, assegurando cobertura de clientes,
tipos corretos e consistência estrutural.
Parâmetros:
dados_integrados (pd.DataFrame): base integrada resultante das uniões.
clientes_df (pd.DataFrame): base de clientes original.
Retorno:
pd.DataFrame: base validada e ajustada.
"""
logger = logging.getLogger()
if dados_integrados is None or dados_integrados.empty:
logger.warning(
"A base integrada está vazia. Tentativa de reintegração será forçada."
)
dados_integrados = pd.DataFrame()
logger.info(
"Iniciando Validação Pós-Integração e Tratamento de Dados Consolidados."
)
# 1. Verificação de cobertura dos clientes
ids_integrados = (
dados_integrados["cliente_id"].nunique()
if "cliente_id" in dados_integrados.columns
else 0
)
ids_origem = clientes_df["cliente_id"].nunique()
if ids_integrados != ids_origem:
logger.audit(
f"Inconsistência detectada: {ids_origem} clientes na origem, {ids_integrados} na base integrada."
)
ids_ausentes = set(clientes_df["cliente_id"]) - set(
dados_integrados["cliente_id"]
)
if ids_ausentes:
registros_ausentes = clientes_df[
clientes_df["cliente_id"].isin(ids_ausentes)
].copy()
registros_ausentes = registros_ausentes.assign(
venda_id=np.nan,
valor=np.nan,
data_venda="Desconhecido",
campanha_id="Não Participou",
canal="Não Informado",
resposta="Não",
data_envio=pd.Timestamp("1970-01-01"),
data_acesso=pd.Timestamp("1970-01-01"),
tipo_acesso="Outros",
duracao_minutos=0,
)
# Garante que todas as colunas estejam presentes
for col in dados_integrados.columns:
if col not in registros_ausentes.columns:
registros_ausentes[col] = np.nan
registros_ausentes = registros_ausentes[dados_integrados.columns]
dados_integrados = pd.concat(
[dados_integrados, registros_ausentes], ignore_index=True
)
logger.info(
f"Reintegração de {len(ids_ausentes)} registros ausentes concluída."
)
# 2. Remoção de duplicatas por e-mail
if "email" in dados_integrados.columns:
duplicados_email = dados_integrados.duplicated(subset=["email"]).sum()
if duplicados_email > 0:
dados_integrados = dados_integrados.drop_duplicates(
subset=["email"], keep="first"
)
logger.info(f"{duplicados_email} duplicatas removidas na coluna 'email'.")
# 3. Remoção de duplicatas por cliente_id
if "cliente_id" in dados_integrados.columns:
duplicados_id = dados_integrados.duplicated(subset=["cliente_id"]).sum()
if duplicados_id > 0:
dados_integrados = dados_integrados.drop_duplicates(
subset=["cliente_id"], keep="first"
)
logger.info(f"{duplicados_id} duplicatas removidas na chave 'cliente_id'.")
# 4. Conversão da coluna data_venda para datetime
if "data_venda" in dados_integrados.columns:
dados_integrados["data_venda"] = pd.to_datetime(
dados_integrados["data_venda"], errors="coerce"
)
dados_integrados["data_venda"].fillna(pd.Timestamp("1970-01-01"), inplace=True)
logger.info(
"Coluna 'data_venda' convertida para datetime e valores inválidos corrigidos."
)
# 5. Preenchimento padrão em colunas críticas
preenchimento_default = {
"canal": "Não Informado",
"resposta": "Não",
"tipo_acesso": "Outros",
"duracao_minutos": 0,
"campanha_id": "Não Participou",
"data_envio": "1970-01-01",
"data_acesso": "1970-01-01",
}
dados_integrados.fillna(preenchimento_default, inplace=True)
logger.info(
"Campos críticos com valores ausentes preenchidos com padrões definidos."
)
# 6. Conversão e validação de tipos finais
tipos_esperados = {
"cliente_id": "int64",
"idade": "int64",
"valor": "float64",
"email": "object",
"data_venda": "datetime64[ns]",
}
for col, tipo in tipos_esperados.items():
if col in dados_integrados.columns:
try:
if tipo == "int64":
dados_integrados[col] = (
pd.to_numeric(dados_integrados[col], errors="coerce")
.fillna(0)
.astype(int)
)
elif tipo == "float64":
dados_integrados[col] = pd.to_numeric(
dados_integrados[col], errors="coerce"
).astype(float)
elif tipo == "datetime64[ns]":
dados_integrados[col] = pd.to_datetime(
dados_integrados[col], errors="coerce"
).fillna(pd.Timestamp("1970-01-01"))
else:
dados_integrados[col] = dados_integrados[col].astype(tipo)
logger.info(f"Coluna '{col}' convertida para tipo '{tipo}'.")
except Exception as e:
logger.warning(f"Falha ao converter '{col}' para '{tipo}': {str(e)}")
logger.info(
f"Validação pós-integração concluída. Total de registros finais: {len(dados_integrados)}"
)
return dados_integrados
# Aplicação da validação pós-integração
dados_integrados = validar_tratar_dados_integrados(dados_integrados, clientes_df)
2025-07-13 16:03:20,686 - [INFO] - Iniciando Validação Pós-Integração e Tratamento de Dados Consolidados. 2025-07-13 16:03:20,692 - [AUDIT] - Inconsistência detectada: 5000 clientes na origem, 3005 na base integrada. 2025-07-13 16:03:20,711 - [INFO] - Reintegração de 1995 registros ausentes concluída. 2025-07-13 16:03:20,713 - [INFO] - 119 duplicatas removidas na coluna 'email'. 2025-07-13 16:03:20,774 - [INFO] - Coluna 'data_venda' convertida para datetime e valores inválidos corrigidos. 2025-07-13 16:03:20,782 - [INFO] - Campos críticos com valores ausentes preenchidos com padrões definidos. 2025-07-13 16:03:20,789 - [INFO] - Coluna 'cliente_id' convertida para tipo 'int64'. 2025-07-13 16:03:20,792 - [INFO] - Coluna 'idade' convertida para tipo 'int64'. 2025-07-13 16:03:20,795 - [INFO] - Coluna 'valor' convertida para tipo 'float64'. 2025-07-13 16:03:20,798 - [INFO] - Coluna 'email' convertida para tipo 'object'. 2025-07-13 16:03:20,804 - [INFO] - Coluna 'data_venda' convertida para tipo 'datetime64[ns]'. 2025-07-13 16:03:20,806 - [INFO] - Validação pós-integração concluída. Total de registros finais: 4881
4.8 Validação Final e Métricas de Qualidade da Base Consolidada
Neste bloco fazemos uma checagem completa da base consolidada antes de finalizar o pipeline. Primeiro, tratamos campos que ainda possam ter valores ausentes. Em seguida, reaplicamos as transformações derivadas, como faixa de valor, ano da venda e faixa etária, para garantir que todos os dados – inclusive os registros reintegrados – estejam padronizados. Por fim, analisamos duplicatas, validamos a unicidade das chaves e registramos métricas de volume e integridade em logs. A base está então pronta para ser exportada ou utilizada por etapas seguintes do projeto.
def tratar_valores_ausentes(df):
"""
Preenche valores ausentes em campos críticos da base consolidada.
"""
logging.info("Iniciando tratamento final de valores ausentes.")
if "venda_id" in df.columns:
df["venda_id"].fillna(df["venda_id"].mean(), inplace=True)
if "valor" in df.columns:
df["valor"].fillna(df["valor"].mean(), inplace=True)
if "tipo_acesso" in df.columns:
df["tipo_acesso"].fillna("Desconhecido", inplace=True)
logging.info("Preenchimento de valores ausentes realizado com sucesso.")
return df
def validar_e_testar_qualidade(df):
"""
Executa testes finais de qualidade: duplicatas, métricas e valores ausentes.
"""
logging.info("********* Iniciando Validação Final e Testes de Qualidade *********")
if "email" in df.columns:
duplicadas_email = df.duplicated(subset=["email"]).sum()
logging.info(f"Duplicados restantes na coluna 'email': {duplicadas_email}")
if "cliente_id" in df.columns:
duplicadas_id = df.duplicated(subset=["cliente_id"]).sum()
logging.info(f"Duplicados restantes na chave 'cliente_id': {duplicadas_id}")
logging.info("Validação final concluída. Métricas principais:")
logging.info(f"- Total de registros na base: {len(df)}")
logging.info(f"- Clientes únicos: {df['cliente_id'].nunique()}")
logging.info(
f"- Vendas únicas: {df['venda_id'].nunique() if 'venda_id' in df.columns else 0}"
)
logging.info(f"- Dimensões da base: {df.shape}")
nulos = df.isnull().sum()
nulos_relevantes = nulos[nulos > 0]
if not nulos_relevantes.empty:
logging.info(f"Valores ausentes por coluna:\n{nulos_relevantes}")
else:
logging.info("Nenhum valor ausente encontrado nas colunas principais.")
return df
# 1. Tratamento de nulos finais
dados_final = tratar_valores_ausentes(dados_integrados)
# 2. Reaplicação de transformações derivadas
dados_final = transformar_dados(dados_final, "Base Integrada Final")
# 3. Validação final com logs e métricas
dados_final = validar_e_testar_qualidade(dados_final)
2025-07-13 16:03:21,034 - [INFO] - Iniciando tratamento final de valores ausentes. 2025-07-13 16:03:21,040 - [INFO] - Preenchimento de valores ausentes realizado com sucesso. 2025-07-13 16:03:21,042 - [INFO] - Iniciando transformações avançadas para a base 'Base Integrada Final'. 2025-07-13 16:03:21,047 - [INFO] - Coluna 'tipo_acesso' padronizada. Valores únicos alterados de 3 para 3. 2025-07-13 16:03:21,058 - [INFO] - Coluna 'canal' padronizada. Valores nulos corrigidos: 0. 2025-07-13 16:03:21,063 - [INFO] - Coluna derivada 'faixa_valor' criada com faixas definidas. 2025-07-13 16:03:21,070 - [INFO] - Coluna 'ano' criada com base na 'data_venda'. 2025-07-13 16:03:21,074 - [INFO] - Coluna derivada 'faixa_idade' criada para segmentação etária. 2025-07-13 16:03:21,077 - [INFO] - Transformações concluídas para 'Base Integrada Final'. Novas colunas criadas: ['faixa_valor', 'ano', 'faixa_idade'] 2025-07-13 16:03:21,079 - [INFO] - ********* Iniciando Validação Final e Testes de Qualidade ********* 2025-07-13 16:03:21,082 - [INFO] - Duplicados restantes na coluna 'email': 0 2025-07-13 16:03:21,085 - [INFO] - Duplicados restantes na chave 'cliente_id': 0 2025-07-13 16:03:21,087 - [INFO] - Validação final concluída. Métricas principais: 2025-07-13 16:03:21,090 - [INFO] - - Total de registros na base: 4881 2025-07-13 16:03:21,093 - [INFO] - - Clientes únicos: 4881 2025-07-13 16:03:21,095 - [INFO] - - Vendas únicas: 2805 2025-07-13 16:03:21,098 - [INFO] - - Dimensões da base: (4881, 17) 2025-07-13 16:03:21,103 - [INFO] - Valores ausentes por coluna: faixa_idade 82 dtype: int64
4.9 Armazenamento Flexível e Dinâmico dos Dados Processados
Neste bloco vamos armazenar os dados tratados em formatos distintos — como CSV, JSON e Parquet — garantindo flexibilidade para consumo futuro e interoperabilidade com outras ferramentas. Também incluímos controle de logs para assegurar rastreabilidade da operação e facilitar a identificação de falhas no salvamento.
def armazenar_dados(df, nome_base, formato="csv", diretorio="dados/output"):
"""
Essa função salva os dados processados em formatos variados com controle de logs e validações.
Parâmetros:
df (pd.DataFrame): DataFrame a ser armazenado.
nome_base (str): Nome do arquivo sem extensão.
formato (str): Formato do arquivo ('csv', 'json', 'parquet').
diretorio (str): Caminho para salvar os arquivos.
Retorno:
bool: True se salvo com sucesso, False caso contrário.
"""
logger = logging.getLogger()
if df is None or df.empty:
logger.warning(f"O DataFrame '{nome_base}' está vazio. Nenhum arquivo foi salvo.")
return False
os.makedirs(diretorio, exist_ok=True)
caminho_completo = os.path.join(diretorio, nome_base)
try:
if formato == "csv":
df.to_csv(f"{caminho_completo}.csv", index=False, encoding="utf-8")
logger.info(f"Arquivo salvo com sucesso em: {caminho_completo}.csv")
elif formato == "json":
df.to_json(
f"{caminho_completo}.json",
orient="records",
lines=True,
force_ascii=False
)
logger.info(f"Arquivo salvo com sucesso em: {caminho_completo}.json")
elif formato == "parquet":
df.to_parquet(f"{caminho_completo}.parquet", index=False)
logger.info(f"Arquivo salvo com sucesso em: {caminho_completo}.parquet")
else:
logger.error(f"Formato '{formato}' não suportado.")
return False
return True
except Exception as e:
logger.error(f"Erro ao armazenar o arquivo '{nome_base}': {str(e)}")
return False
armazenar_dados(clientes_df, "clientes_processados", formato="csv")
armazenar_dados(vendas_df, "vendas_processadas", formato="parquet")
armazenar_dados(marketing_df, "marketing_processado", formato="json")
armazenar_dados(acessos_df, "acessos_processados", formato="csv")
2025-07-13 16:03:21,355 - [INFO] - Arquivo salvo com sucesso em: dados/output\clientes_processados.csv 2025-07-13 16:03:21,394 - [INFO] - Arquivo salvo com sucesso em: dados/output\vendas_processadas.parquet 2025-07-13 16:03:21,407 - [INFO] - Arquivo salvo com sucesso em: dados/output\marketing_processado.json 2025-07-13 16:03:21,417 - [INFO] - Arquivo salvo com sucesso em: dados/output\acessos_processados.csv
True
5. Backup Automatizado com Controle de Versão
Neste bloco vamos implementar uma rotina de backup para salvar a base consolidada com controle de versão. O nome do arquivo será gerado dinamicamente com base na data e hora da execução, garantindo a rastreabilidade dos resultados. Isso permite manter um histórico de versões da base final, facilitando comparações, auditorias e recuperação de informações em execuções futuras do pipeline.
def gerar_backup(
df,
nome_base="base_integrada",
formato="csv",
pasta_backup=os.path.join("dados", "backup"),
):
"""
Realiza backup do DataFrame com controle de versão baseado em timestamp.
Parâmetros:
df (pd.DataFrame): base de dados consolidada.
nome_base (str): nome-base do arquivo de saída.
formato (str): formato de exportação ('csv', 'json', 'parquet').
pasta_backup (str): diretório onde os backups serão armazenados.
Retorno:
bool: True se o backup foi concluído com sucesso, False caso contrário.
"""
logger = logging.getLogger()
if df is None or df.empty:
logger.warning(f"Backup ignorado: base '{nome_base}' vazia ou inexistente.")
return False
try:
os.makedirs(pasta_backup, exist_ok=True)
# Geração do nome versionado
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
nome_arquivo = f"{nome_base}_versao_{timestamp}"
caminho_final = os.path.join(pasta_backup, nome_arquivo)
if formato == "csv":
df.to_csv(f"{caminho_final}.csv", index=False, encoding="utf-8")
elif formato == "json":
df.to_json(
f"{caminho_final}.json", orient="records", lines=True, force_ascii=False
)
elif formato == "parquet":
df.to_parquet(f"{caminho_final}.parquet", index=False)
else:
logger.error(f"Formato '{formato}' não suportado para backup.")
return False
logger.info(f"Backup concluído com sucesso: {caminho_final}.{formato}")
return True
except Exception as e:
logger.error(f"Erro ao realizar backup da base '{nome_base}': {str(e)}")
return False
# Execução do backup com versionamento
gerar_backup(
dados_final,
nome_base="dados_processados",
formato="csv",
pasta_backup="dados/backup",
)
2025-07-13 16:03:21,762 - [INFO] - Backup concluído com sucesso: dados/backup\dados_processados_versao_20250713_160321.csv
True
6. Geração Automatizada de Relatório do Pipeline
Neste bloco vamos encerrar o pipeline com uma etapa de geração automatizada de relatório. O processo inclui a captura do tempo total de execução, a avaliação do status final (sucesso ou falha) e o registro detalhado das ações realizadas, incluindo possíveis falhas de auditoria. O relatório final será salvo em formato de texto (.txt), servindo como documentação oficial da execução, permitindo rastreabilidade e facilitando auditorias futuras.
# Adiciona caminho do módulo externo de validação
# sys.path.append(os.path.abspath(os.path.join(os.getcwd(), 'scripts')))
sys.path.append(os.getcwd())
from validacao_dados import auditar_qualidade_dados
# Regras de estrutura e negócio
regras_estrutura = {
"clientes_df": {
"colunas_obrigatorias": ["cliente_id", "nome", "idade", "email"],
"tipos_colunas": {"cliente_id": int, "nome": str, "idade": int, "email": str},
}
}
regras_negocio = {
"clientes_df": {
"email_invalido": {
"regra": "~@df['email'].str.contains(r'^[\\w\\.\\-]+@[\\w\\.\\-]+\\.\\w+$')",
"descricao": "E-mails inválidos",
},
"idade_negativa": {"regra": "@df['idade'] < 0", "descricao": "Idade negativa"},
}
}
# Função auxiliar para gerar o relatório final
def concluir_pipeline(status_execucao, logs_detalhados, tempo_inicial, tempo_final, diretorio_relatorio="logs", base_final=None):
"""
Gera relatório completo da execução do pipeline com métricas reais.
Parâmetros:
status_execucao (str): "SUCESSO" ou "FALHA"
logs_detalhados (list): Lista de mensagens de auditoria e diagnóstico
tempo_inicial (float): Timestamp de início
tempo_final (float): Timestamp de fim
diretorio_relatorio (str): Caminho onde o relatório será salvo
base_final (pd.DataFrame): Base final consolidada, usada para gerar métricas
"""
import os
import logging
from datetime import datetime
logger = logging.getLogger()
if not logger.hasHandlers():
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
formatter = logging.Formatter("%(asctime)s - [%(levelname)s] - %(message)s")
handler.setFormatter(formatter)
logger.addHandler(handler)
try:
os.makedirs(diretorio_relatorio, exist_ok=True)
tempo_total = tempo_final - tempo_inicial
data_execucao = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# Cabeçalho do relatório
relatorio = f"""
===============================
RELATÓRIO DO PIPELINE DE DADOS
===============================
📅 Data de Execução : {data_execucao}
✅ Status Final : {status_execucao}
⏱️ Tempo Total : {tempo_total:.2f} segundos
"""
# Estatísticas da base final
if base_final is not None and not base_final.empty:
relatorio += "\n------------------------------\n📊 Métricas de Processamento\n------------------------------\n"
relatorio += f"✔ Registros finais consolidados: {len(base_final)}\n"
if "cliente_id" in base_final.columns:
relatorio += f"✔ Clientes únicos: {base_final['cliente_id'].nunique()}\n"
if "venda_id" in base_final.columns:
relatorio += f"✔ Vendas únicas: {base_final['venda_id'].nunique()}\n"
enriquecidas = [col for col in ["faixa_valor", "faixa_idade", "ano"] if col in base_final.columns]
if enriquecidas:
relatorio += f"✔ Atributos enriquecidos: {', '.join(enriquecidas)}\n"
# Verificação de duplicatas e nulos
duplicatas_email = base_final.duplicated(subset=["email"]).sum() if "email" in base_final.columns else 0
duplicatas_id = base_final.duplicated(subset=["cliente_id"]).sum() if "cliente_id" in base_final.columns else 0
relatorio += f"✔ Duplicatas removidas: email = {duplicatas_email}, cliente_id = {duplicatas_id}\n"
nulos = base_final.isnull().sum()
nulos_relevantes = nulos[nulos > 0]
if not nulos_relevantes.empty:
relatorio += f"✔ Colunas com valores ausentes: {', '.join(nulos_relevantes.index.tolist())}\n"
# Logs detalhados de auditoria e execução
relatorio += "\n------------------------------\n🔍 Auditoria e Eventos\n------------------------------\n"
for log in logs_detalhados:
relatorio += f"▶ {log}\n"
# Caminho do arquivo
caminho_relatorio = os.path.join(diretorio_relatorio, "relatorio_pipeline.txt")
with open(caminho_relatorio, "w", encoding="utf-8") as arquivo:
arquivo.write(relatorio.strip())
logger.info(f"📄 Relatório gerado com sucesso: {caminho_relatorio}")
except Exception as e:
logger.error(f"❌ Erro ao gerar relatório final: {str(e)}")
# Execução Final do Pipeline
tempo_inicial = time.time()
logs_detalhados = []
try:
# Conversão preventiva de tipos para validação
clientes_df = clientes_df.astype(
{"cliente_id": "int64", "nome": "str", "idade": "int64", "email": "str"}
)
# Auditoria de qualidade
logs_detalhados.append("▶ Iniciando auditoria da base de clientes.")
auditoria_aprovada = auditar_qualidade_dados(
clientes_df,
"clientes_df",
regras_estrutura["clientes_df"],
regras_negocio["clientes_df"],
)
if not auditoria_aprovada:
raise Exception("Auditoria de clientes não aprovada.")
logs_detalhados.append("Auditoria concluída com sucesso.")
status_execucao = "SUCESSO"
except Exception as e:
logging.error(f"Erro durante execução final: {e}")
logs_detalhados.append(f"Erro: {e}")
status_execucao = "FALHA"
# Finalização do pipeline
tempo_final = time.time()
concluir_pipeline(status_execucao, logs_detalhados, tempo_inicial, tempo_final, base_final=dados_final)
2025-07-13 16:03:21,915 - [INFO] - Iniciando auditoria de estrutura para clientes_df. 2025-07-13 16:03:21,918 - [INFO] - Iniciando auditoria de regras de negócio para clientes_df. 2025-07-13 16:03:22,388 - [INFO] - [clientes_df] Auditoria concluída com sucesso! 2025-07-13 16:03:22,397 - [INFO] - 📄 Relatório gerado com sucesso: logs\relatorio_pipeline.txt
7. Arquivos Gerados e Estrutura de Diretórios
Ao longo do pipeline que construimos aqui foram gerados arquivos e organizados de forma padronizada em diretórios específicos. Essa organização facilita a rastreabilidade, a auditoria e o reaproveitamento das bases processadas, mantendo controle de histórico e versionamento automático.
📁 Diretórios Criados
✅ logs/ → Contém os registros detalhados da execução do pipeline.
✅ dados/output/ → Armazena os dados processados em diferentes formatos.
✅ dados/backup/ → Guarda versões anteriores dos arquivos com controle de histórico.
📄 Arquivos Gerados pelo Pipeline
🔹 Logs:
📌 logs/pipeline.log → Contém registros de cada etapa do pipeline.
📌 logs/relatorio_pipeline.txt → Relatório final com status da execução.
🔹 Dados Processados:
📌 dados/output/clientes_processados.csv → Dados de clientes limpos e validados.
📌 dados/output/vendas_processadas.parquet → Dados de vendas após integração e transformação.
📌 dados/output/marketing_processado.json → Dados de campanhas processados.
📌 dados/output/acessos_processados.csv → Registros de acessos tratados.
🔹 Backups Versionados:
📌 dados/backup/clientes_processados_YYYYMMDD_HHMMSS.csv
📌 dados/backup/vendas_processadas_YYYYMMDD_HHMMSS.parquet
📌 dados/backup/marketing_processado_YYYYMMDD_HHMMSS.json
📌 dados/backup/acessos_processados_YYYYMMDD_HHMMSS.csv
(Backups gerados automaticamente com timestamp para rastreabilidade completa.)
8. Conclusão Geral
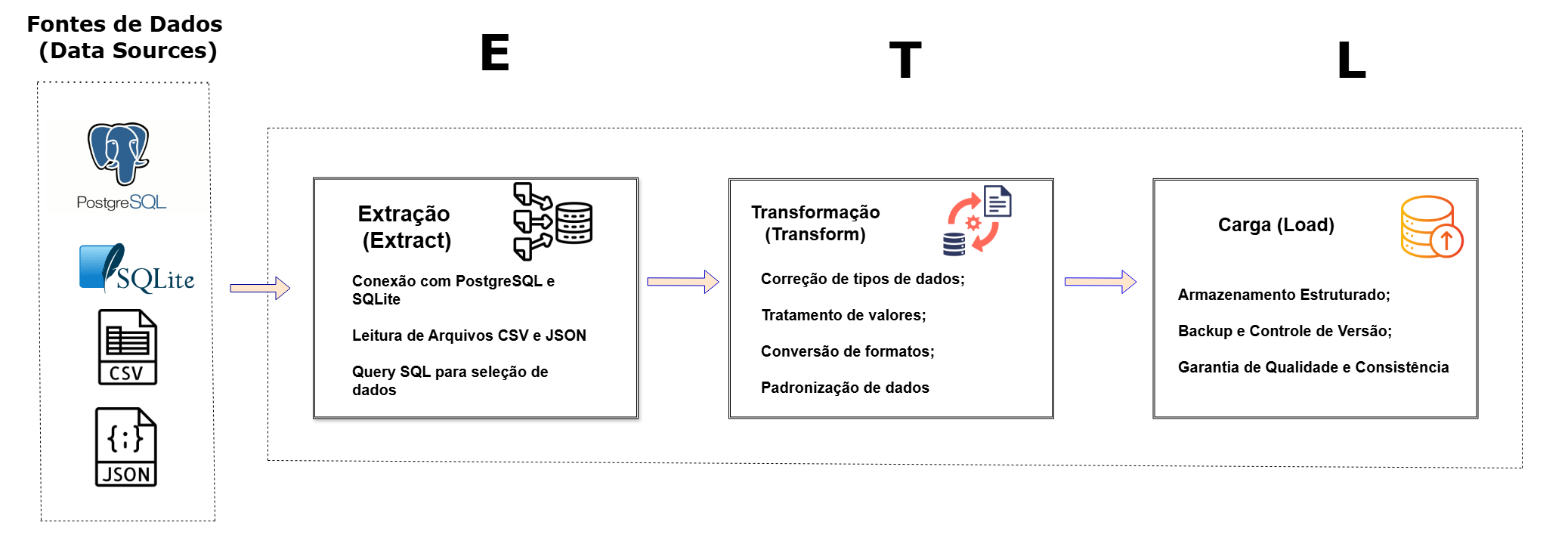
Chegamos ao final deste trabalho, e construímos um pipeline que não só integra dados de diferentes fontes, como também garante qualidade, segurança e escalabilidade, estabelecendo uma base sólida para análises estratégicas e aprimoramentos futuros.
Principais Destaques :
- Integrar dados de múltiplas fontes (Postgre, SQLite, CSV, JSON).
- Assegurar a qualidade dos dados, aplicando limpezas, correções e validações automatizadas.
- Garantir a escalabilidade, rastreabilidade e segurança, com logs detalhados e backups automáticos.
- Preparar os dados para análises avançadas, incluindo transformações enriquecidas e criação de colunas derivadas.